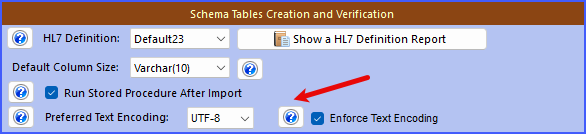
You can now handle Text Encoding in your HL7 messages using our CORE HL7 Software shown below:
Some History: HL7 Encoding Options - ANSI vs. UTF-8
HL7 messages were originally designed as plain ASCII text—even field delimiters like |, ^, and \ are part of that standard format. That means traditional HL7 messages shouldn't include special characters like bullets (•), accented letters (é, ñ), or fractions (½, ¼). However, in modern healthcare messaging, systems sometimes need these extended characters—especially for representing names, notes, or user-friendly text. That’s where the encoding selection matters.
-
ANSI (Windows-1252) supports a limited set of extended characters that are common in Western languages, like • (bullet), ½ (one-half), smart quotes (“ ”), accented letters, and more. But any characters outside this range may not display correctly.
-
UTF-8, on the other hand, supports the entire Unicode set—so you can safely include emojis, characters from non-Western languages, and any symbols without corruption BUT you have to make sure that your destination HL7 Listener can support that.
Even so, HL7 best practices recommend avoiding these extended characters entirely when possible. Instead, use HL7 Escape Sequences to represent special content, e.g., reserved delimiter characters or special formatting. Examples include:
-
\F\ for | (field separator),
-
\S\ for ^ (component separator),
-
\T\ for & (sub-component separator),
-
\Xnn...\ for explicit hexadecimal values.
You can find a list of some of these escape codes and guidelines on HL7 escaping in the online help for the CORE SQL Engine HERE.
For further information on how HL7 Escape Sequences work you will have to visit https://www.HL7.org.
HL7 Messages: ANSI vs UTF-8 When Sending Over TCP/IP
It's important to remember that HL7 messages are just TEXT and are sent over TCP/IP to a waiting HL7 Listener in a byte stream where each byte represents one byte of the HL7 message. This "byte stream" does not itself have any particular "Encoding" and just represents the string (or TEXT) value provided to the HL7 Sender (like our CORE HL7 TCP/IP Sender) by the entity which created the message. The tricky part comes IF the HL7 Sender needs to deliver a message which contains special characters (like • € ƒ … † ‡ ˆ ‰ ‹ Œ “ ” – — ™ œ Ÿ ¼ ½ ¾ © ®).
Consider just one character the bullet (•). In ANSI text encoding this character is represented by ONE byte (HEX 95). In UTF-8 text encoding this character is represented by 3 bytes (HEX E2, 80, and A2). So the challenge is to know which value the waiting HL7 Listener is expecting, OR does it even matter. Can the HL7 Listener automatically detect and translate the encoding (like our CORE HL7 Listener can).
HL7 Messages: ANSI vs UTF-8 in MS SQL Server
When storing HL7 messages in SQL Server with our CORE HL7 MS SQL Schema Engine, character encoding matters more than you might think. HL7 messages aren’t always just letters and numbers—they can include symbols like •, ™, or €. Whether those characters are preserved correctly depends on how the data is encoded before it reaches the database.
Two Encoding Options
When HL7 messages are inserted into your SQL Server database, whether ANSI or UTF-8 works correctly depends on how the database is configured—especially the collation.
-
ANSI (Windows-1252)
-
Some databases are aligned with ANSI code pages and will store characters like • or € without issue.
-
But if your database collation doesn’t match ANSI expectations, the results can be garbled.
-
For example: on a SQL Server using the SQL_Latin1_General_CP1_CI_AS collation, inserting an ANSI message caused special characters to break.
-
UTF-8
-
UTF-8 is widely supported in modern SQL Server setups and is often the safer choice for preserving all special characters.
-
If your database supports it, using UTF-8 avoids most compatibility issues.
-
However, some older SQL Servers or collations may not fully support UTF-8, which can cause errors or strange results.
In our case in our testing lab our database Collation was SQL_Latin1_General_CP1_CI_AS. ANSI HL7 Messages produced garbled message data for any special characters (•, ™, or €). The reliable solution was to set the Preferred Text Encoding to UTF-8 and enable Enforce Text Encoding. That way, even if your HL7 partner sends ANSI, the program converts it to UTF-8 before inserting, ensuring characters remain intact.
The Enforce Text Encoding Option
To reduce the risk of bad characters sneaking into your database, the CORE MS SQL Engine includes the Enforce Text Encoding checkbox.
-
When enabled, the software automatically detects the encoding of incoming HL7 messages.
-
If the message was sent in ANSI, but you’ve chosen UTF-8 as your preferred encoding, it will re-encode the text before inserting into SQL Server.
-
This way, you can safely accept messages from partners who are still using ANSI, while storing everything consistently in your database.
For example:
-
If you insert an ANSI message directly into SQL Server configured for UTF-8, special characters like • or € may show up as garbled.
-
With Enforce Text Encoding turned on, the program converts them properly, ensuring that the characters remain intact.
The key takeaway: the choice depends on how your database handles text internally. If your SQL Server collation doesn’t properly support ANSI, you’ll need UTF-8. If it doesn’t support UTF-8, you may need to stick with ANSI. That’s where the Enforce Text Encoding option comes in—ensuring consistency regardless of what your HL7 partners send.
Why You Still Need to Test
Encoding issues are tricky because they often only show up when special characters appear. That’s why it’s important to:
-
Set your preferred encoding (ANSI or UTF-8).
-
Turn on Enforce Text Encoding if you want automatic conversion.
-
Import test HL7 messages containing special characters.
-
Verify the characters are stored and retrieved correctly in SQL Server.
Final Thought
There isn’t a one-size-fits-all answer. If your partners only ever send ANSI, you may choose to keep things simple. But if you expect a mix—or want to prepare for the future—selecting UTF-8 with Enforce Text Encoding enabled is usually the safest option.